
Applying Event Sourcing and CQRS in a legacy project
I was told to work on a legacy project, a mix between a management system and reporting tool. The high level picture of the architecture was:
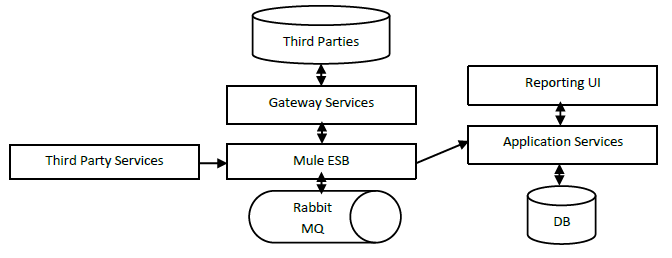
An ESB (Mule) is listening events raised by Third Party Services. Each event passes over some queues and each queue aims to enrich data from Gateway Services. Finally, the events are sent to the Application Service. The Application Services and Gateway Services have been designed following tier architecture with Application, Services and Data Access tiers.
I’m sure this kind architecture may sound familiar to most of you. So, let’s go for the drawbacks behind:
- UI slowness: Users need reports from Application Service (read operations). But Application Service is performing write operations from events at the same time.
- Concurrency: Application Service has to deal with concurrent events from ESB.
- Audit: Application Service has to manually audit the changes against every entity in the DB.
- Traceability: Not possible to figure out the sequence of changes after an event: don’t have proper snapshots and data history.
- Scalability: We need to scale either the whole Application Service or Gateway Services or the whole applications within Mule ESB.
How does Event Sourcing and CQRS architecture help here?
This architecture isolates the services by the components which perform write and read operations (it helps in points 1 and 2). Also, this architecture works directly with the events rather than entities. By means, the events themselves are stored into the DB, in order by time (it helps in points 3 and 4). Since the components are now more granular, it helps on point 5 scalability.
Nevertheless, it also has some “disadvantages”:
What about eventual consistency?
Eventual consistency means that the changes will not be displayed UI directly when the Application Service receives an update. There will be always some delay. This is something we need to agree first with stakeholders.
What about validation?
Events are our source of truth, but there will be collisions and constraints in the data for sure.
First Step: ESB replacement
Why do we need a Mule ESB instance to orchestrate the incoming events? If you find a very good reason, go for it; otherwise replace your Mule ESB instance into consumer services and orchestrate the logic only with Rabbit MQ which is:
- Easier to deploy/scale: Just adds a new consumer for a queue.
- More app granularity: For example, if a consumer/producer app is not working fine, we can detect this easily.
- Technology agnostic: We can decide to implement an app consumer/producer using a framework which may work better for some purposes.
Therefore, thanks to Rabbit MQ, we still can offer high availability and fault tolerance.
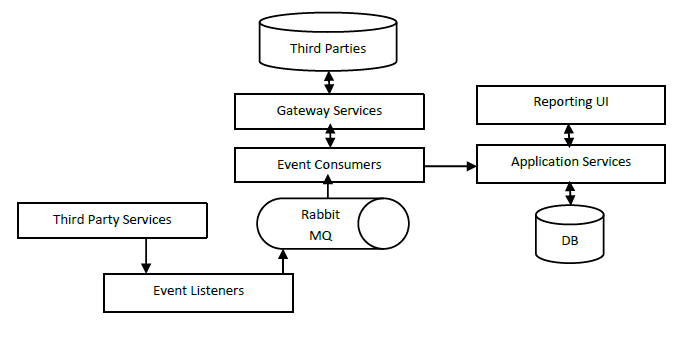
Second Step: Event Sourcing
By refactoring the ESB layer into a consumer services approach we did not face yet any of the above drawbacks. The main bottleneck is still in the database where we use the same application Application Service for write and read operations. Let’s introduce Event Store tables:

These Event Store tables can be within a single database instance or in multiple database instances. The important bit is that the Event Store stores only events. So the Application Service and consumer services insert these events (instead of updating entities). For example, in the Attributes Event Store, we have:
- Event 1: Entity X contains an attribute distributionStatus with value “Pending”.
If the Application Service receives that the entity X is ready to be distributed, then the Attributes Event Store would have the new event 2:
- Event 2: Entity X contains an attribute distributionStatus with value “Ready”.
- Event 1: Entity X contains an attribute distributionStatus with value “Pending”.
This way we also can have data history for free and possibility to run a replay of data and traceability.
It’s important to remark that we should use optimistic locking to update the Event Store. A solution for doing this is to add another column “Version” and check always if the new event we want to add, matches with the version we did read at the beginning of the event transaction. More info here.
Finaly Step: CQRS (Command Query Responsability Segregation)
Application Service application is also used as reporting purposes. Now, when using Event Store databases, these read operations will have to read all the events for a single entity, so probably the latency will be a way worse. We need to separate Application Service into two components: Query components (for read operations) and Command components (write operations).
The Command applications will manage the incoming events and store these events into the Event Store. The Query applications will read the data from the Read Storage. The Read Storage is like a “user” friendly database of the Event Store. Example, we have 10 events for different attributes of an entity in the Event Store, and in the Read Storage, we will have these 10 events mapped to either a single row or a table with two foreign keys, etc. For this, we need a new component Event Handler who manages the mapping between Event Store <-> Read Storage.
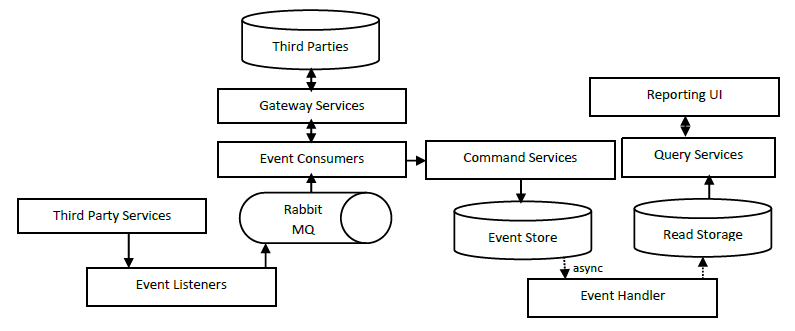
There are many options to implement the Event Handler component and you can configure it to define the frequency for invalidate/refresh your data in the Read Storage which at the end will mean the eventual consistency in your solution.