
Distributed Architectures
When thinking on distributed architecture solutions, we need to have many things in mind to choose the right one. Some of these are:
- Scalability: how can scale my system?
- Message size: number of requests we need to manage
- Message Priorities
- Eventual Consistency: do we need my response just now and quick? Does it exist?
Let’s see some approaches.
Case #1: Three-Layer Architecture
Presentation layer: Angular / React.s / Plain JSes Service Layer: Spring Boot / Micronaut / node.js Data Layer: Oracle DB / Cassandra

This is the classic and more general approach, but still quite valid nowadays.
In order to scale up, we need to deploy more instances in Presentation and Services layers plus using a load balancer like nginx or ELB. The complexity in Data layer is higher since it requires to apply replication patterns for resiliance.
Requirements
- Stateless business layer
- Framework flexibility
- Load Balancer
- Low eventual consistency: depending on the resiliance patterns in data layer.
Disadvantages
- High latency
- Single purpose: Only to handle user requests.
Case #2: Sharding
This is an extension of Case #1, but having shards or partitions for different networks.
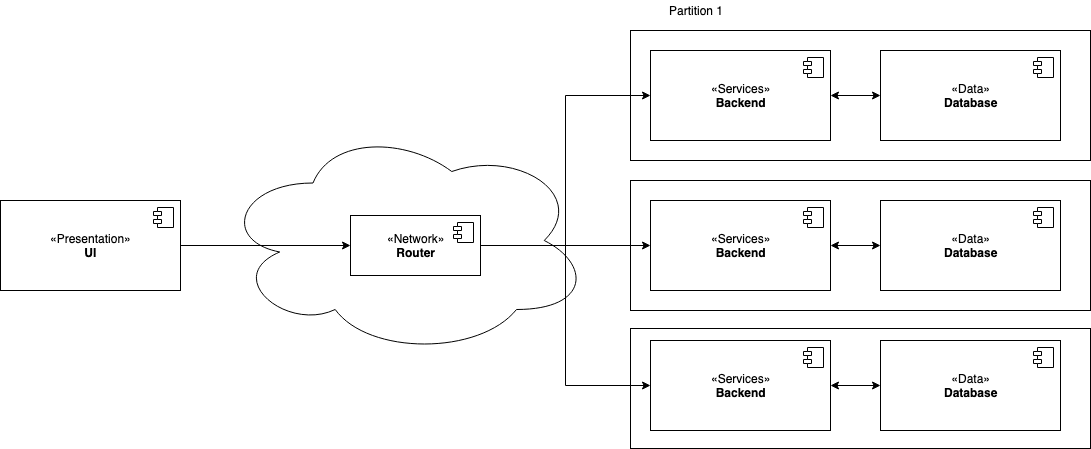
This architecture used to be chosen when deploying in different regions. It requires to route messages to scale our instances better based on services or regions.
Requirements
- Same as Case #1
- Network team to deal with management of a more complex network
- Configuration server to manage configuration, naming and sync like Zookeeper
Disadvantages
- Same as Case #1
- More complex architecture
- Difficulty on monitoring all the shards
Case #3: Eventing
Producers: Send events to Event Processor Event Processor: Kafka or ESB Consumers: Listen for events from Event Processor
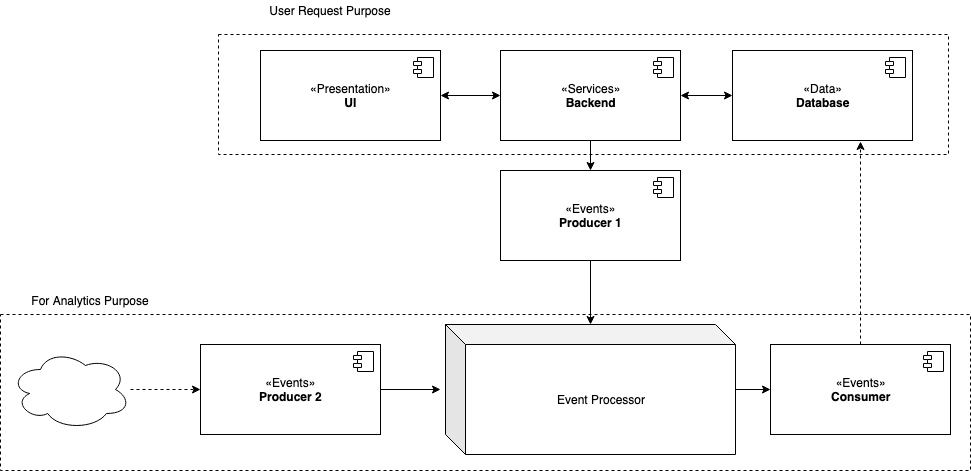
This should be used when the solution needs to hande user requests with high latency and can have eventual consistency, and also for enrichment or analytics purposes.
This architecture should be used when it requires multiple purposes like user requests handling, integrations, analytics, etc.
But wait? Kafka or ESB? Kafka has nothing to do with ESB! Let me ellaborate the advantanges and disadvantanges, as well as when to use each one as an event processor role.
Kafka as Event Processor
Kafka can be used as an event storage and it’s a perfect match when doing Command Query Responsability Segregation (CQRS) architectures.
Moreover, Kafka is a persistent storage, so we could live having a database working as an aggregator of the data in Kafka. This database could be used by the services layer for having very low latency in Read operations.
Requirements
- Immutable Data: Events. Advantages: rollback in history and rewind.
- Event Rewind
- Messages rollback
- Troubleshoting
- Eventual Consistency
- High scalability
Disadvantages
- No global ordering (If we use Kafka: only within partitions, so it needs to think carefully about how to partition)
ESB as Event Processor
I confess I’m not a big fan of ESB services like Mule. Small services can do the same as good and fast as these services.
ESB used to be useful as an integration layer among many third parties or gateways. So, it’s a perfect match when working on enrichment applications.
Requirements
- Flexibility to add all kind of integrations: between HTTP to AMQP, or REST JSON to XML, etc.
Disadvantages
- Hard to scale up concrete integrations
- Scalability: depending on the service we finally use though
- Might need a messaging broker like RabbitMQ
Conclusion
Besides the architectures, there are more general challenges that need to be solved individually in distributed architectures as logging or service discovery or fault tolerance. The solution for all these problems are the same: apply the very well-known patterns like Circuit Breaker, Event Bus, etc.