
The Netflix Machine Learning Infrastructure
When building machine learning models to work over different areas, data scientists usually need to deal with these two situations:
- How can I deploy my model and see results?
- Will my model affect the rest somehow?
Mainly, these two questions are about infrastracture and collaboration, which requires devops engineers to efficiently solve it. So, we have now two roles here where a data scientist should focus on: 1.- Write a model for a paradigm 2.- Deploy it and see the results
And a devops engineer should focus on: 1.- Run multiple models independently in a cluster infrastructure 2.- Build a data warehouse system to store/trigger the results
We’ll quickly introduce the Netflix Machine Learning insfrastructure whereby Metaflow is used as an interface among the data scientist and devops worlds.
A Machine Learning Stack
- Data Warehouse: Cluster Infrastructure and Distributed Storage
- Compute Resources: Cluster Resources Management
- Job Scheduler: Model Execution Management
- Versioning: Model Versioning
- Collaboration Tools: Model Repository
- Model Deployment
- ML Libraries
Data Scientist viewpoint
A data scientists will focus on writing models using any ML Library and will deploy its models with some Model Deployment tool.
DevOps viewpoint
A devops will rule multiple versioned models using a Job scheduler over a compute resources composed by a cluster infrastructure and a data warehouse.
The Netflix Machine Learning Stack
- Data Warehouse: Spark + S3
- Compute Resources: Titus (alternative: Kubernetes)
- Job Scheduler: Meson (alternative: Airflow)
- Versioning: Metaflow
- Collaboration Tools: Nteract
- Model Deployment: Metaflow
- ML Libraries: R or Python
Titus
Titus is a container management platform that natively works with AWS. It manages a large number of AWS EC2 instances for service workloads. From the Titus documentation:
“Titus is a framework on top of Apache Mesos, a cluster-management system that brokers available resources across a fleet of machines. Titus consists of a replicated, leader-elected scheduler called Titus Master, which handles the placement of containers onto a large pool of EC2 virtual machines called Titus Agents, which manage each container’s life cycle. Zookeeper manages leader election, and Cassandra persists the master’s data. The Titus architecture is shown below.”
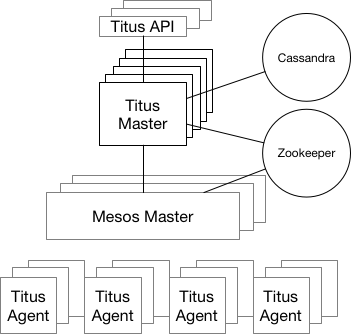
Meson
Meson is a workflow management tool to provide task isolation with Titus (and then Apache Mesos) and job scheduling:
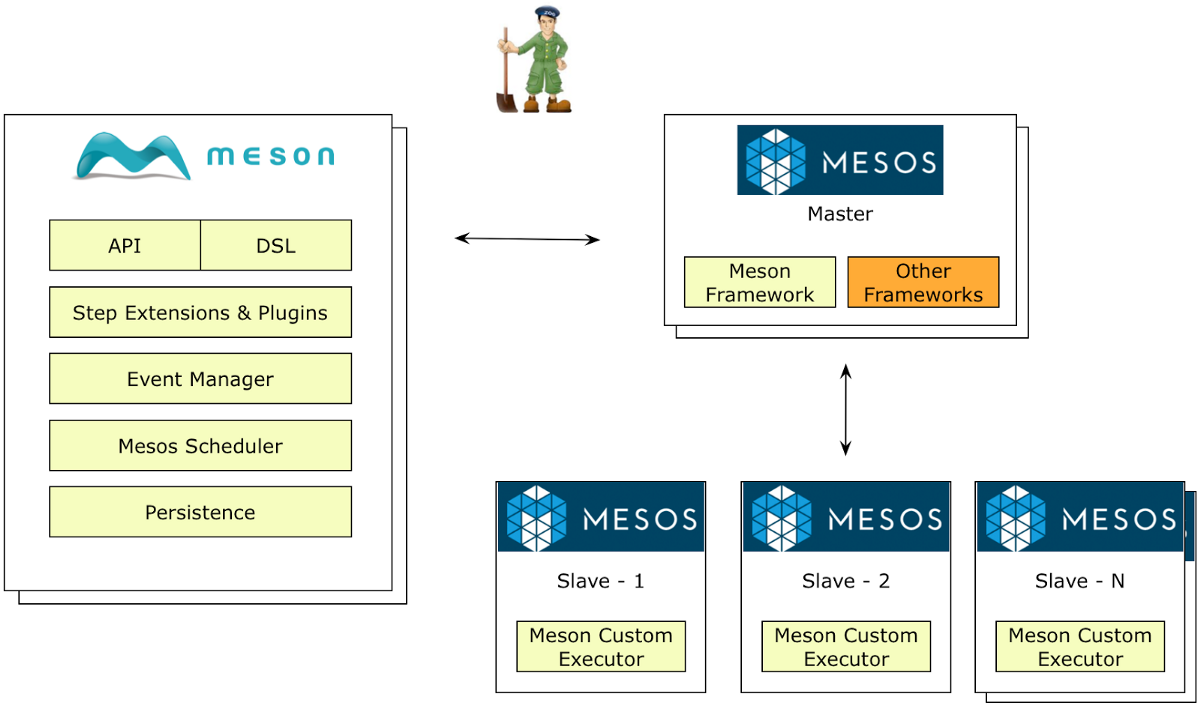
NTeract
Why do we need a new tool if we already have GIT as a source repository? Well, NTeract is more that a source repository. Data scientists also need a way to collaborate in live when writting common models or any kind of notebooks. NTeract is a desktop application and allows parallel editing among different users. Personally, I didn’t know this tool before and I can say it’s really cool
Metaflow
This tool allows data scientists to wrap the above layers of the architecture in a single place and tool. Metaflow can be used for python or R languages.
Let’s introduce the next example taken from here:
from metaflow import FlowSpec, step
class MyFlow(FlowSpec):
@step
def start(self):
self.x = 0
self.next(self.a, self.b)
@step
def a(self):
self.x += 2
self.next(self.join)
@step
def b(self):
self.x += 3
self.next(self.join)
@step
def join(self, inputs):
self.out = max(i.x for i in inputs)
self.next(self.end)
MyFlow()
This is how to run it:
> python myscript.py run
Now, these are the features:
- Resume with steps: Each Step has a persistent state
The fields like self.x is persisted after each method annotated with @step. Therefore, we can resume our model in a concrete step:
> python myscript.py resume B
This is really helpful for troubleshooting purposes.
- Scalability: can use titus annotations in each step
Each method annotated with @step is independently scheduled on the Job Scheduler. Moreover, we can define the Titus compute resources declarativelly with the @titus annotation:
// ...
@titus(cpu=16, gpu=1)
@step
def a(self):
self.x += 2
self.next(self.join)
@titus(memory=20000)
@step
def b(self):
self.x += 3
self.next(self.join)
// ...
- Data Load from S3 using Table
Well, all about this is to load large data, big data, and analyse it. So, how can we load efficiently large data with Metaflow?
from metaflow import Table
// ...
@titus(memory=20000, network=20000)
@step
def load(self):
df = Table('my_s3_user', 'a_table')
self.next(self.end)
// ...
- Versioning with namespaces
# Access coworker 1's runs
namespace('user:user1')
run = Flow('MyFlow').latest_run
print(run.id)
print(run.tags)
# Access coworker 2's runs
namespace('user:user2')
run = Flow('MyFlow').latest_run
print(run.id)
print(run.tags)
# Access everyone's runs
namespace(None)
run = Flow('MyFlow').latest_run
print(run.id)
- Using a simple Meson create command to deploy
python myscript.py meson create
- See the metrics of models via Notebooks and Metaflow hosting
Data Scientits are allowed to expose the job results via endpoints:
from metaflow import WebServiceSpec
from metaflow import endpoint
class MyWebService(WebServiceSpec):
@endpoint
def show_data(self, request_dict):
result = self.artifacts.flow.x
return { 'x': result }
curl http://host/show_data
{"x": 3}
Conclusions
This article is based on a InfoQ conference by Ville Tuulos from Netflix.