
RabbitMQ vs Apache Kafka
RabbitMQ uses queue data structures (FIFO). Data is transient and optimised for efficient write and read operations from either end of the sequence.
Apache Kafka uses log data structure (each message is uniquely identified by sequence numbers). Append only and ordered by time. Data is persistent.
RabbitMQ
Let’s summarize the main concepts:
- Publichers send messages to Exchanges
- Exchanges route messages to Queues or other Exchanges
- Consumers read from Queues

RabbitMQ works on Virtual Hosts which allows multi-tenant archicture and isolate the configuration within a virtual host.
Routing: How Exchanges route messages to Queues
- Fanout Exchange: Send the message to every queue. Each consumer receives every message. Easy to scale out by adding more consumers.
- Direct Exchange: Use the Routing Key within the message to route the message to one Queue.
- Topic Exchange: Again, use the Routing Key as a regular expression to route messages to Queues. For example, route all the messages with routing key “booking.*” to Queue A.
- Header Exchange: Similar, but using message headers. No scale very well.
- Random Exchange: Send the message to random exchange. It works like a load balancer. It cannot garantee the order.
- Consistent Hashing Exchange: Partition messages across queues via hashing function over the Routing Key, header or any message property.
- Sharding Plugin: Distribute messages across queues over multiple hosts via hasing function on the Routing Key.
Automatic Routing when Queue Limit reached
We can configure queues to apply some limitations like: (1) length, (2) size and/or (3) time limits (TTL). So, when a queue limit is reached, the message is automatically routed to a Deadletter exchange to avoid message loss.
Queues Types
-
Ephemeral: Auto-Delete Queue/Exchanges: when the last consumer is unsuscribed, the queue is auto deleted itself. Queue Expiration: a time limit for a queue life. Exclusive Queues: private queues
-
Lazy Queues: Memory optimized queues
-
Priority Queues No longer FIFO. Publisher sets priority on messages. Queue limits can be tricky here.
Apache Kafka
Kafka is deployed as a cluster of nodes and partitioned using topics. Kafka replicates across multiple nodes.
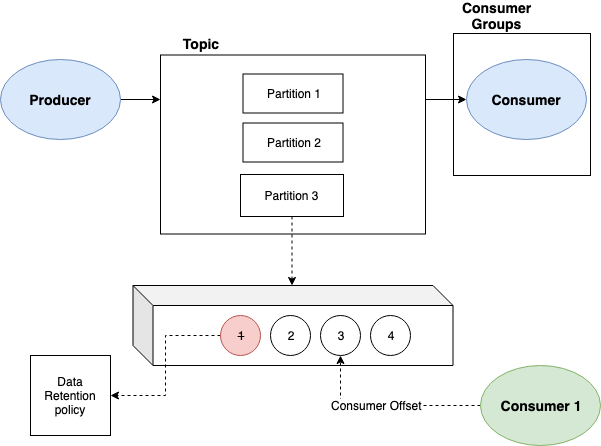
The main concepts:
- Producers append Messages to the end of the Topic.
- Message: unique identify by a record key.
- Topic: a set of partitions for a topic.
- Partition: log structure which is replicated across all the nodes.
- Consumer Groups: a number of consumers that listen at least one partition within a topic.
- Consumers: keep track their position in the partitions they consume from - this is called the consumer offset.
Data is automatically removed from partitions using a data retention policy. This policy is driven by time limits or partition size.
Event Sourcing
Periodically, kafka cleans up old versions of messages (by record key) and keep latest version only.
This makes Apache Kafka works as an Event Store being a single source of truth at the center of an architecture.
Avro Schema Registry
What about if my message has changed the format? This is if my message had one field only, and after a change, it has two fields now. Apacke Kafka uses Apache Avro schema registry to safely control evolution of schemas and be backward compability.
Conclusion
The main difference between Kafka and RabbitMQ is that Apache Kafka is designed for scalability and intended to be used as an event store, whereby RabbitMQ is designed to route messages.
We could design our architecture using either Kafka or RabbitMQ but we should focus on the problem to solve instead. For example, if we use RabbitMQ to route messages, we need to take into consideration the message ordering and the queue load. Imagine we process much faster the messages to ship a product and very slow the messages to cancel a purchase. We would be shipping the product even when the purchase was cancelled! On the other hand, if we use Kafka, we should carefully make decisions on which topics to use.
Moreover, what about the message priority? In RabbitMQ, we have the Priority Queues which is not recommended to be used: it’s preferred to replicate the structure into a private virtual host to handle priority messages and route these messages to it. For Apache, we should provide priority topics for this.
Also, if our problem requires to read old messages, we should use Kafka instead unless we want to add a persistent storage and use RabbitMQ which sounds like to reinvent the wheel.
Finally, let’s summarize the problems that each one tries to solve:
RabbitMQ
- AMQP connector
- Easily Evolvable Topologies
- Transient Messages
- Flexible Message Routing
Apache Kafka
- Data Replication
- Event Store
- Simple Scaling
- Message History
- Persistent Messages
https://www.youtube.com/watch?v=sjDnqrnnYNM (by Jack Vanlightly)