
Refactoring an ESB based architecture
At my previous post, I gave an introduction to some distributed architectures. Also, I confess that I’m not a big fan of ESB based architectures: these solutions only work fine in integrations with third parties and still I’m being generous. Let me explain why I dislike this kind of solutions.
Let’s start introducing how our architecture looks like at first:
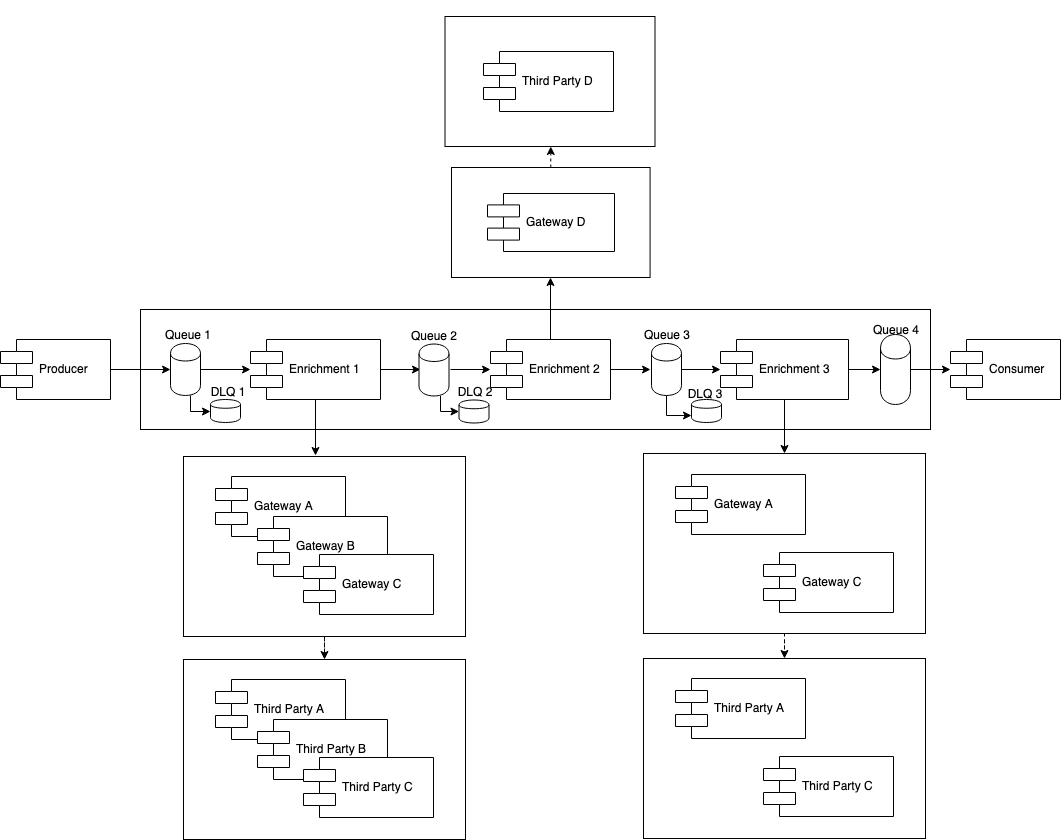
Responsabilities:
- Producers: sends events or requests to our ESB layer via queue or HTTP.
- Enrichments: listen messages from an IN (a queue), process the message using flow manipulations and outputs it to an OUT (another queue).
- Gateway: Service in between a third party and enrichments.
Obviously, not all the architectures that use an ESB work the same way, but as a very summary, the esb layer listens messages, processes them and sends data to the output.
Before starting a complete redesign of our architecture, we need to make clear what the problem/s we want to resolve here. It might sound obvious but I don’t think it’s in real life: most of the times we feel the needs to upgrade our architectures to the latest trendy solutions/frameworks/versions just because it’s cool. So, what problems do we want to solve?
Inefficient resources usage
In the above architecture, we would need at least Nx(Gateway) instances + 1 Consumer + 1 Producer + the 1 ESB instance. This ESB instance have a few disadvantages:
- Large applications
ESB applications used to work as integrators among HTTP, REST, JSON, XML, and a large etc. However, it implies lot of embedded frameworks in the application and then usage lot of cpu/memory resources.
- Not very flexible for scaling up
Even though it depends on how we build our applications in the ESB, at the end we need to deploy a whole ESB instance to scale up.
- Complex to logging and troubleshooting
Assuming we use message tracker numbers or correlation IDs, still follow or monitor messages can be quite tedious. At the end, we’ll came up for using a logging infrastructure to cope with an ESB layer as a must.
Quality of service
Hard to deal with massive load or failure in services. What about whether if we receive a massive of requests or one of the gateways started failing? The ESB layer does not provide anything to deal with or anything to monitor these scenarios. So, again, this is something that we need to take care of. This issue is solved by just applying well-known distributed patterns like circuit breaker or bulkhead for fail-fast. We’ll see more about this later.
More about this, how can we leverage requests from a concrete source? Can we prioritize it? We need a solution that allow us to implement things like this.
Refactor 1: Replace ESB
The first refactor is about to replace each flow application with a single applications that we’ll call here integrator services. As a good practice, a flow and the new instance must do only one thing.
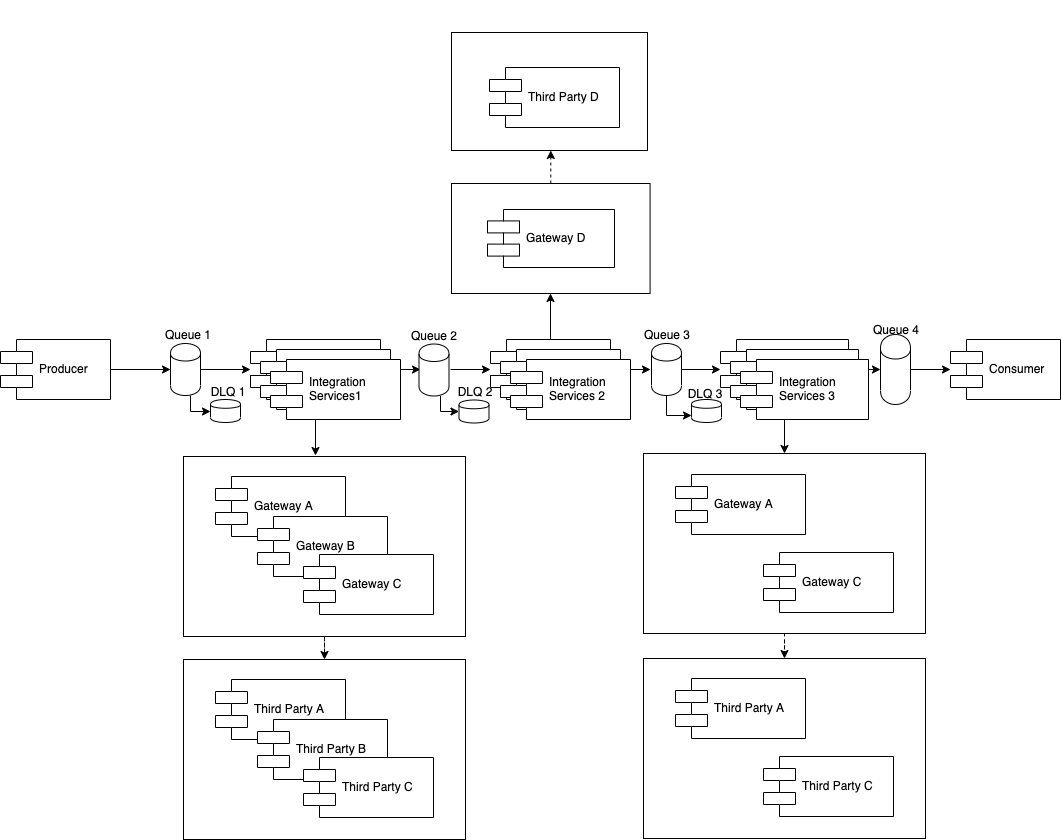
What do we achieve with this refactor?
- We can scale up at instance level / flow level.
- Light-weight instances: less memory comsuption.
But we’re still way far of our target:
- Still very inefficient resources usage: now we’d need at least to Nx(Gateway) instances + 1 Consumer + 1 Producer + Mx(Integration services) instances.
- We need to somehow monitor the instances.
- Still nothing about quality of service.
Refactor 2: Replace Gateways
What is a gateway? A service that routes a request to a third party. Why do we need a service for this where nowadays there are a lot of solutions that solve exactly the same problem such as: Zuul, Spring Cloud Gateway or Amazon API Gateway. For on-premises architectures, I would choose Zuul which is a very well known solution rather than Spring Cloud Gateway bearing in mind that both are supported and work pretty fine with Spring Boot solutions. For cloud architectures (in AWS stack), Amazon API Gateway should be our choice and a big benefit of it is that a request from Amazon API Gateway can trigger an AWS Lambda (I will revisit this in the appendix).
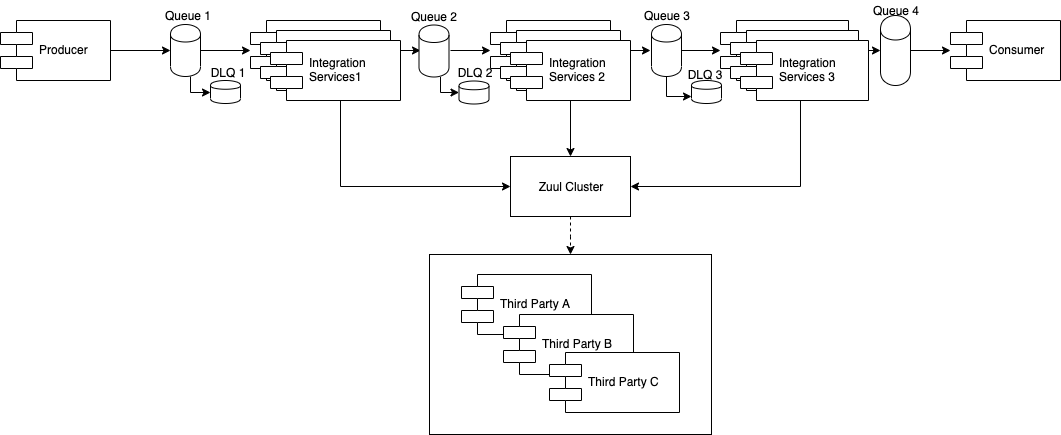
- A more light-weight architecture: 1 Zuul Cluster + 1 Consumer + 1 Producer + Mx(Integration services) instances.
- All the benefits in-built with Zuul as an example we can define strategies and pattern in Zuul with rules to leverage the requests.
Refactor 3: Quality of Service
Let’s separate the concerns and use the better of the services ecosystem and message queue systems. In this section, we’ll be using RabbitMQ as our message broker and Spring Boot instances using profiles:
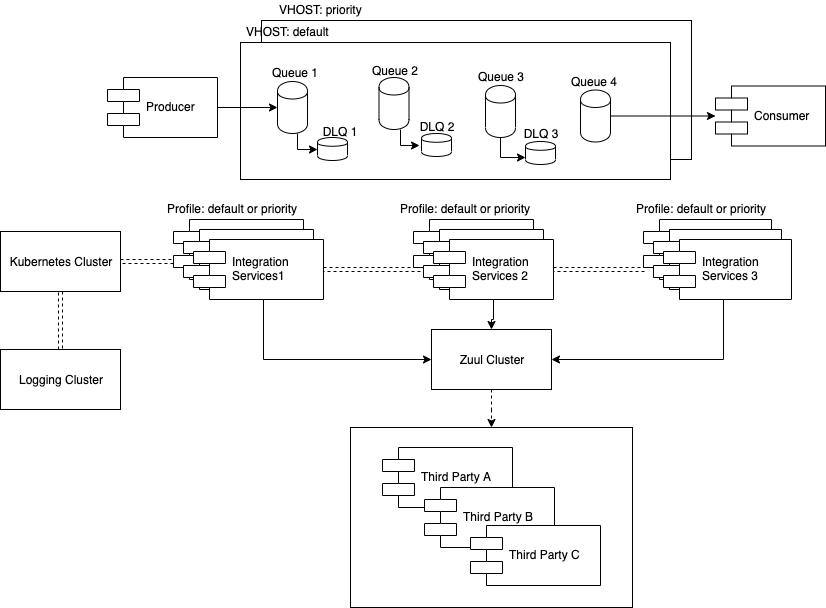
From the services ecosystem, this refactor is about to redesign our Integrator services to be queue-agnostic and profile based. So that depending on configuration, it will listen and write to the queue in a concrete virtual host.
Oh wait… now we have instances that need to be configured differently… how are we going to manage this in production? Let’s embrace kubernetes. This is a very well known infrastructure tool and don’t want to speak more about it. In here, it will allow to easily change configuration using ConfigMaps and deploy instances in our on-premises nodes. Also, we configure our services and Kubernetes using a logging cluster like Elastic stack as an example (this is only in on premises solutions)
From message queue systems:
- Virtual hosts in RabbitMQ allows to deploy the same queue structure but adding the benefit of customise the priority of the requests. Therefore, we can have a virtual host dedicated for a customer or for more priority requests and we can deploy a few integrator services to work with this virtual host.
- Apply strategies to handle lot of requests: routing to dead-letter queues when a condition is met.
Conclusion
I think the better conclusion after writing this post is that the very first architecture was trying to “reinvent the wheel” and looking for solutions that were already solved by other well designed tools/frameworks such as Kubernetes, RabbitMQ, Zuul, ElasticSearch, Spring Cloud … The key is to make clear what the problems are, what boundaries your infrastructure have and get the better benefit of your stack technology.
Appendix: Cloud Solution
I didn’t want to finish this post before making the comparison between an on-premise and a cloud solution. Let’s imagine we can use the AWS stack for our solution, how would it look like?
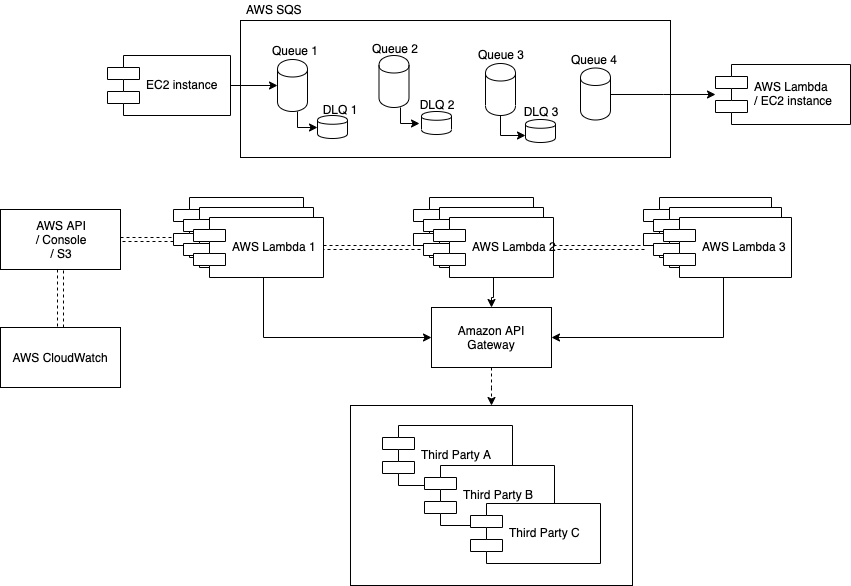
I don’t have a very large experience in working with cloud solutions but I used AWS stack solutions a lot and have been studying the solutions they provide for a while. Let’s review the final cloud diagram:
- The Integrator services can be replaced by AWS Lambda. These AWS Lambda services can be triggered either by AWS API Gateway or by AWS SQS (a queue).
- The producer would be our only 24x7 service. The consumer is optional depending of our solution. So, this must be replaced by an EC2 instance.
- We don’t need Kubernetes or Zuul here since AWS provides API or the Console to deal with your instances and configuration. Everything would be centralized. Moreover, we can implement our whole infrastucture in templates to deploy everything in one region or another region.
- Also, we have AWS cloudwatch to see our instance logs in one single place.